Latest Sessions
View All Sessions
S20 | Closing the Autoregressive Gap with Continuous Bitstream Diffusion
Georgios Batzolis (University of Cambridge) presents a continuous diffusion language model that represents text as fixed-width binary bitstreams instead of token embeddings. An entropy-gated stochastic sampler concentrates randomness where token uncertainty is highest, which narrows the quality gap to autoregressive models, while the model predicts only O(log V) bits per token rather than a full vocabulary distribution.
Georgios Batzolis (University of Cambridge) presents Entropy-Gated Continuous Bitstream Diffusion. Diffusion language models promise parallel, order-agnostic generation, but on standard benchmarks they have long lagged behind autoregressive models in sample quality and diversity. Recent continuous flow and diffusion models over token embeddings narrowed this gap, suggesting that continuity itself is not the bottleneck. This work pushes the idea further by diffusing over bitstreams: each semantic token is encoded as a fixed-width sequence of binary bits, embedded in continuous space, and recovered from Gaussian noise by an EDM-style denoiser. Because an isolated bit has a known closed-form posterior under Gaussian corruption, the authors introduce a matched-filter residual parameterization, in which the network computes the analytic independent-bit posterior and spends its capacity only on the contextual residual. The largest gains come from the sampler. The deterministic probability-flow sampler is already competitive but over-contractive, reaching good perplexity by undershooting real-data token entropy. An entropy-gated stochastic sampler corrects this by applying Langevin-type churn on an entropy-rate grid, concentrating randomness in high-information regions and staying nearly deterministic elsewhere. On LM1B, a 130M-parameter model reaches a generative perplexity of 59.76 at matched data entropy using 256 function evaluations, surpassing prior diffusion baselines and the autoregressive reference. On OpenWebText it reaches 27.06 using four times fewer steps than prior 1024-step baselines. Because the model predicts O(log V) bitwise logits rather than a vocabulary-sized distribution, it also uses less memory and runs faster, an advantage that grows as vocabularies do.

S19 | ELF: Embedded Language Flows
Keya Hu and Linlu Qiu (MIT) present ELF (Embedded Language Flows), a continuous diffusion language model that runs Flow Matching in continuous embedding space and discretizes to tokens only at the final step. This design makes it easy to adapt image-domain techniques such as classifier-free guidance.
Keya Hu and Linlu Qiu (MIT) present ELF (Embedded Language Flows). Diffusion and flow-based models are the default choice for generating continuous data such as images and video, yet today's leading diffusion language models still work over discrete tokens. ELF (Embedded Language Flows) asks whether continuous models can compete with only minimal special treatment of discreteness. ELF maps tokens into a continuous embedding space using an encoder needed only at training time, then learns a continuous-time Flow Matching process that denoises embeddings from Gaussian noise toward clean ones. It parameterizes the network to predict the clean embedding rather than the velocity, which lets a single shared-weight network handle both denoising and the final decoding step. Discretization happens only at the last step, where that same network projects the embedding through a learned unembedding matrix to token logits, so ELF needs no separate decoder at inference. Because the trajectory stays continuous almost everywhere, techniques from image diffusion such as classifier-free guidance carry over with little change. Across open-web text, machine translation, and summarization, ELF reaches lower generative perplexity than leading discrete models (MDLM, Duo) and concurrent continuous ones (FLM, LangFlow), using fewer sampling steps, roughly ten times fewer training tokens, and no distillation.

S18 | Language Modeling with Spherical Geometry
Justin Deschenaux (EPFL) and Jannis Chemseddine (TU Berlin) present their recent works on hyperspherical language modeling. By lifting tokens onto the sphere, they define language flows along SLERP and vMF paths. The vMF path admits a closed-form score, Hyperspherical flows improve code generation over prior flow language models, and at matched NFE, the PC sampler with vMF paths improves accuracy on Sudoku.
Discrete diffusion samples from a factorized distribution that is strictly less expressive than autoregressive models, while Flow Language Models (FLMs) avoid factorized sampling but add Gaussian noise on one-hot vectors, a noise process with no clear semantic interpretation for text. Both papers explore the sphere as a natural geometry for language flows. By lifting tokens onto the hypersphere, the authors develop spherical language modeling via SLERP and vMF paths. The vMF path has a closed-form conditional score, enabling predictor-corrector samplers on the sphere. Training with rotations avoids materializing one-hot vectors, making it cheaper than standard FLM training. On TinyGSM (code generation), prior FLMs reach roughly 0% accuracy while hyperspherical flows reach 12-18%. At matched NFE, a PC sampler with vMF paths improves accuracy on Sudoku. Joint work with Caglar Gulcehre, Gregor Kornhardt, and Gabriele Steidl.
Featured Videos
View All Videos
How did diffusion LLMs get so fast?
Techniques for accelerating diffusion LLMs, from self-distillation and curriculum learning to KV caching and block diffusion
This video discusses techniques for making diffusion LLMs faster, including self-distillation through time, curriculum learning, confidence scores for unmasking, guided diffusion (FlashDLM), approximate KV caching (dLLM-Cache, dKV-Cache), and block diffusion.
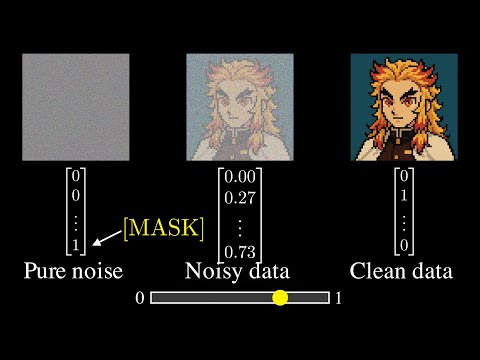
But How Do Diffusion Language Models Actually Work?
Jia-Bin Huang explores several ideas for applying diffusion models to language modeling
Most Large Language Models (LLMs) today are based on Autoregressive models (i.e., they predict texts in a left-to-right order). But diffusion models offer iterative refinement, flexible control, and faster sampling. In this video, we explore several ideas for applying diffusion models to language modeling.

Simple Diffusion Language Models
Quick introduction to Masked Diffusion Language Models (MDLM) by Alexander Rush
Quick introduction to Masked Diffusion Language Models (MDLM) by Alexander Rush
About the Reading Group
Diffusion LLMs are faster, more controllable successors to traditional LLMs and are rapidly gaining adoption. This reading group builds a community for exchanging and debating emerging ideas in this space. While our primary focus is discrete diffusion models for language, we also welcome work on other modalities and applications, such as molecular design, drug discovery, and beyond.
Meet the Organizers

Subham Sahoo
Holds a Ph.D. from Cornell Tech, where he specialized in Diffusion Language Models. He has made foundational contributions to the field, with his work deployed at scale by Google, NVIDIA, and ByteDance across language generation and drug discovery.

Justin Deschenaux
PhD student in Machine Learning at EPFL, advised by Prof. Caglar Gulcehre. Previously interned at Apple MLR. His research interests include diffusion language models, fast generative models, and generalization.
